
Joint Attention Discovery
Abstract
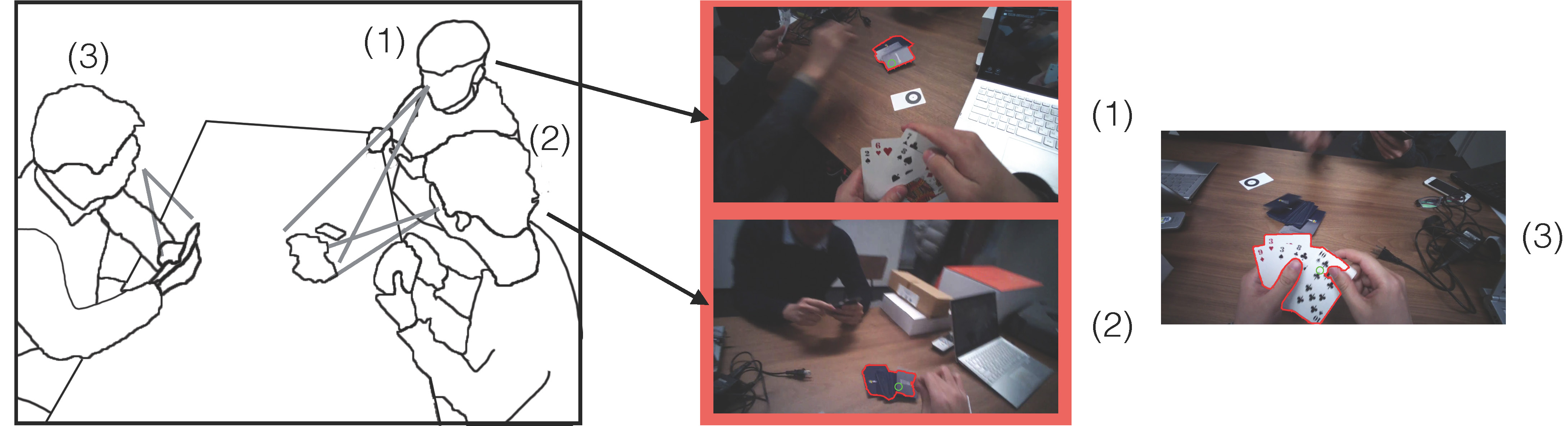
This work aims to develop a computer-vision technique for understanding objects jointly attended by a group of people during social interactions. As a key tool to discover such objects of joint attention, we rely on a collection of wearable eye-tracking cameras that provide a first-person video of interaction scenes and points-of-gaze data of interacting parties. Technically, we propose a hierarchical conditional random field-based model that can 1) localize events of joint attention temporally and 2) segment objects of joint attention spatially. We show that by alternating these two procedures, objects of joint attention can be discovered reliably even from cluttered scenes and noisy points-of-gaze data. Experimental results demonstrate that our approach outperforms several state-of-the-art methods for co-segmentation and joint attention discovery.
Publication:
Y. Huang, M. Cai, H. Kera, R. Yonetani, K. Higuchi, and Y. Sato, "Temporal localization and spatial segmentation of joint attention in multiple first-person videos," Proceedings of IEEE International Conference on Computer Vision Workshop (ICCVW), pp. 2313-2321, 2017.
[pdf]
[poster]
[dataset]
Y. Huang, M. Cai, and Y. Sato. “An Ego-Vision System for Discovering Human Joint Attention.” IEEE Transactions on Human-Machine Systems (THMS) 2020.